
Un modèle d'iA est souvent perçu comme une boîte noire.
Un truc un peu obscur, qui a ingurgité des millions de données, et dont on peine à comprendre ce qu'il en a réellement fait.
Mais c'est beaucoup moins mystérieux que ça en a l'air.
L'entrainement d'un modèle d'iA ne sert qu'à calculer des coefficients.
Voici un cas simple d'un modèle qui "prédit" le poids d'une personne en fonction de sa taille à partir des données d'une centaines d'individus (les petits points) :
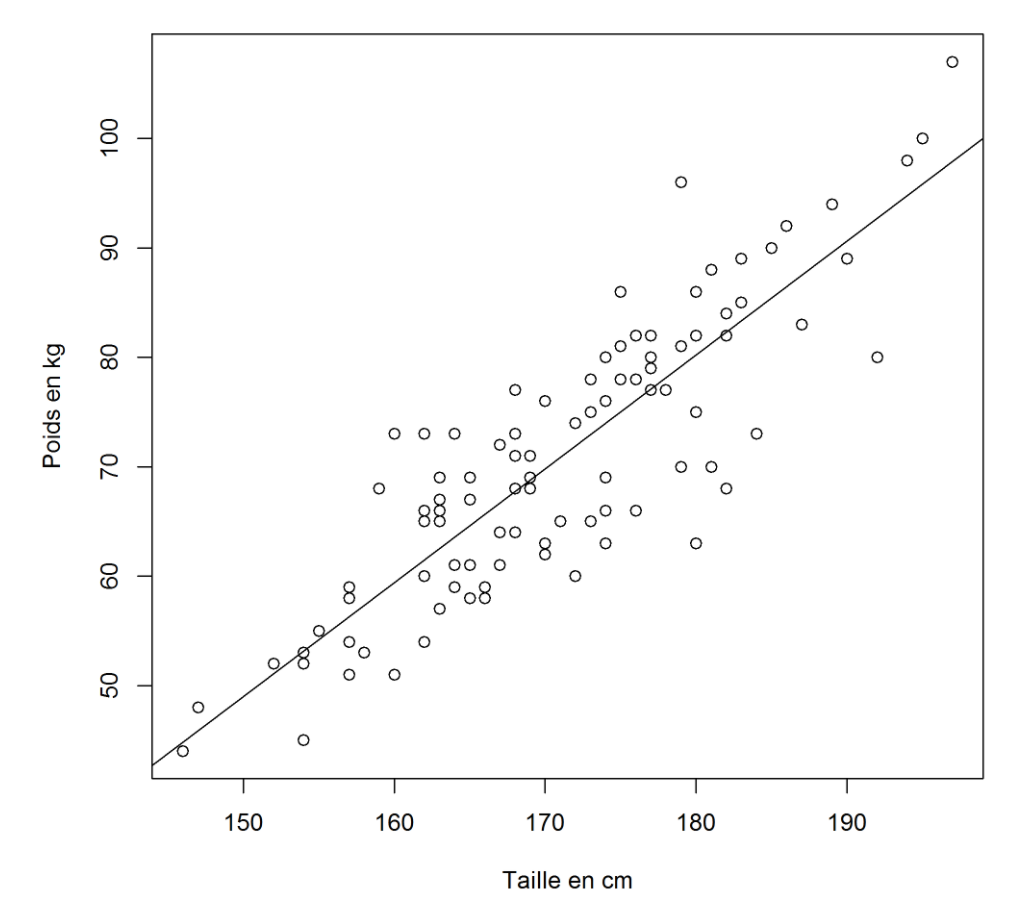
Le modèle comporte uniquement 2 coefficients : la pente et l'origine de la droite qui prédit un poids à partir d'une taille.
Oui, c'est une régression linéraire. Mais c'est quand même plus classe d'appeler ça un "modèle d'intelligence artificielle" ?.
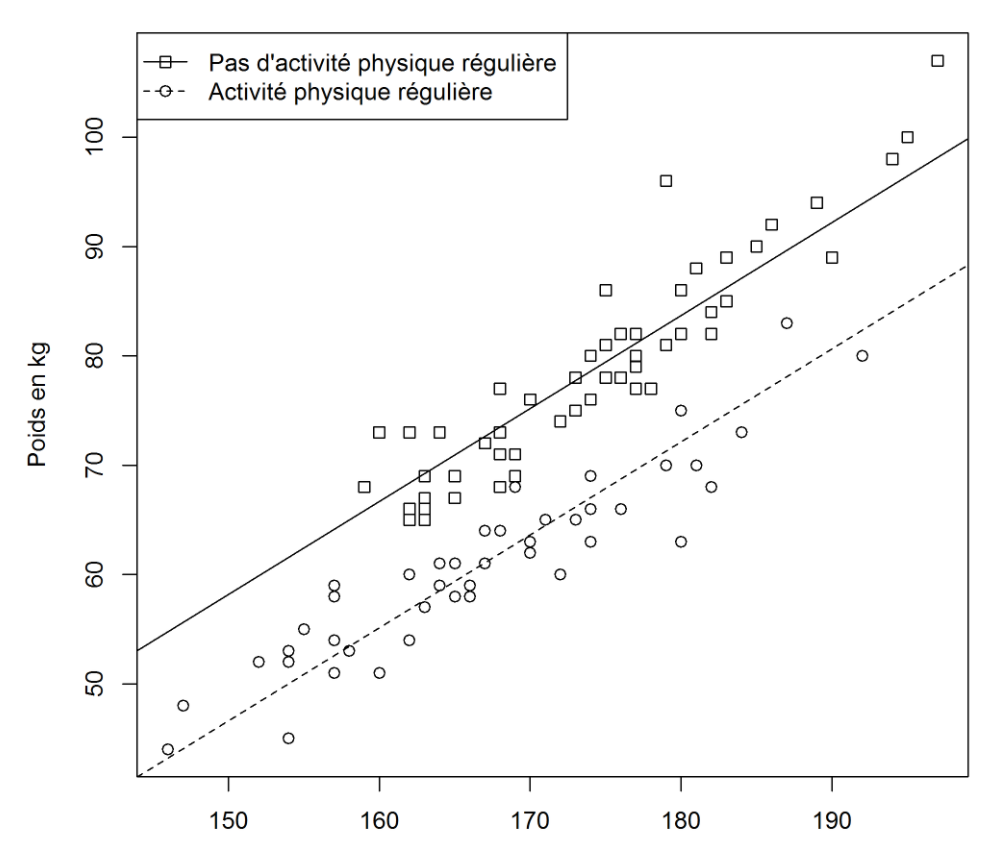
Distinguons maintenant les personnes qui ont une activité physique régulière. On ajoute une dimension dans notre jeu de données. On a maintenant 2 droites différentes, donc 4 coefficients. La prédiction du poids en fonction de la taille est clairement influencée par cette nouvelle dimension.
Ajoutons ensuite l'âge, le sexe, la région dans laquelle la personne vit, son milieu socio-professionnel, la valeur calorique moyenne de ses diners, ...
On pourra entraîner à nouveau notre modèle avec toutes ces données pour affiner sa prédiction. Mais c'est devenu une boîte noire : impossible de représenter facilement tous les cas sur notre graphique. Les coefficients sont en trop grand nombre.
Pourtant, on est encore loin des volumes du deep-learning : le modèle de langage GPT-3, dont les performances sont fascinantes, comporte 175 milliards de coefficients !
Comment comprendre l'intérieur de la boîte noire ? Comment la rendre un peu plus transparente ?
Identifier les facteurs explicatifs
Dans notre travail, dans notre quotidien, ça arrive tout le temps : on veut comprendre ce qu'il se passe.
On veut déterminer les causes d'une situation, ses facteurs d'influence.
Dans son livre "Sortez vos données du frigo", Mick Levy écrit cet exemple pédagogique :
Une entreprise de distribution possède des centaines de points de vente dans toute la France. Certains font de très bons chiffres d'affaires, et d'autres moins.
Comme souvent, on évalue les performances par rapport aux chiffres de l'année dernière, et on essaye de comprendre : qu'est-ce qui explique cette augmentation ? Cette diminution ?
Il y a tellement de facteurs d'influence que les analyses sont hasardeuses...
Essayons une autre méthode : on va entrainer un modèle d'iA pour qu'il puisse prédire le chiffre d'affaires d'un point de vente.
Pour cela, on va enrichir les données de ventes avec pleins d'autres données : la météo, l'activité économique locale, la taille de la zone de chalandise, le nombre de concurrents à proximité, etc ...
En entraînant un modèle d'iA à l'aide de toutes ces données, on obtient 2 résultats intéressants :
- la différence entre le chiffre d'affaire prédit et réel : c'est ainsi que l'on découvre qu'un point de vente réputé performant (pour ses bons chiffres) devrait en fait avoir des chiffres bien meilleurs compte-tenu des atouts dont il dispose,
- le poids relatifs des facteurs qui servent à prédire le chiffre d'affaire.
Au final, l'intérêt du modèle obtenu n'est pas de prédire les futurs chiffres de ventes.
L'intérêt est plutôt d'ouvrir la boîte noire du modèle, et d'analyser les contributions respectives de multiples facteurs pour avoir une compréhension plus objective des causes.
Pour compléter son "instinct" avec des maths.
En prendre de meilleures décisions.
Détecter les biais
Il y a un deuxième intérêt à ouvrir un peu le capot : l'éthique.
Les modèles d'iA prennent une place croissante dans les usages au quotidien. Ils servent à calculer des primes d'assurance, à autoriser des crédits, à reconnaître des individus recherchés, à sélectionner les CV de candidats pour un emploi ...
Et parfois, les résultats partent un peu en vrille.
On a un biais.
Le biais, c'est le covid-19 de l'iA.
Parce que les modèles apprennent des données passées, dont la sélection pèse beaucoup dans les résultats obtenus.
Par exemple, la sélection automatique des CV : si le jeu de données d'entrée comporte un biais (au hasard : les femmes ont des postes avec moins de responsabilités), le modèle va avoir tendance à opérer une sélection indésirable. Il va considérer que le biais (l'inégalité) est un objectif.
Même en anonymisant les données, le modèle va trouver des corrélations (sur les activités extra professionnelles p.ex) qui vont de facto conduire à distordre la sélection.
Voila l'autre enjeu : ouvrir la boîte pour évaluer l'influence de certains facteurs qui ne devraient pas en avoir.
Les outils
OK, ce n'est pas évident de comprendre ce qu'il se passe dans un modèle de 175 milliards de paramètres.
Mais si on commençait par un modèle plus simple ?
Car ce qui compte n'est pas tant l'aptitude à prédire l'avenir, mais plutôt à comprendre les données dont on dispose.
Les interpréter.
Evaluer leurs biais.
La démarche consiste donc d'abord à s'approprier les données dont on dispose déjà, et à les compléter avec d'autres données pour déterminer ce qui compte.
Il existe plusieurs outils pour rendre intelligible un modèle d'iA.
Par exemple, le labo de la MAIF propose la library open-source Shapash , dotée d'une interface de visualisation facile à prendre en main.
Elle classe les dimensions ("features") selon leurs poids relatifs, et permet l'analyse unitaire d'une donnée ("local explanation").
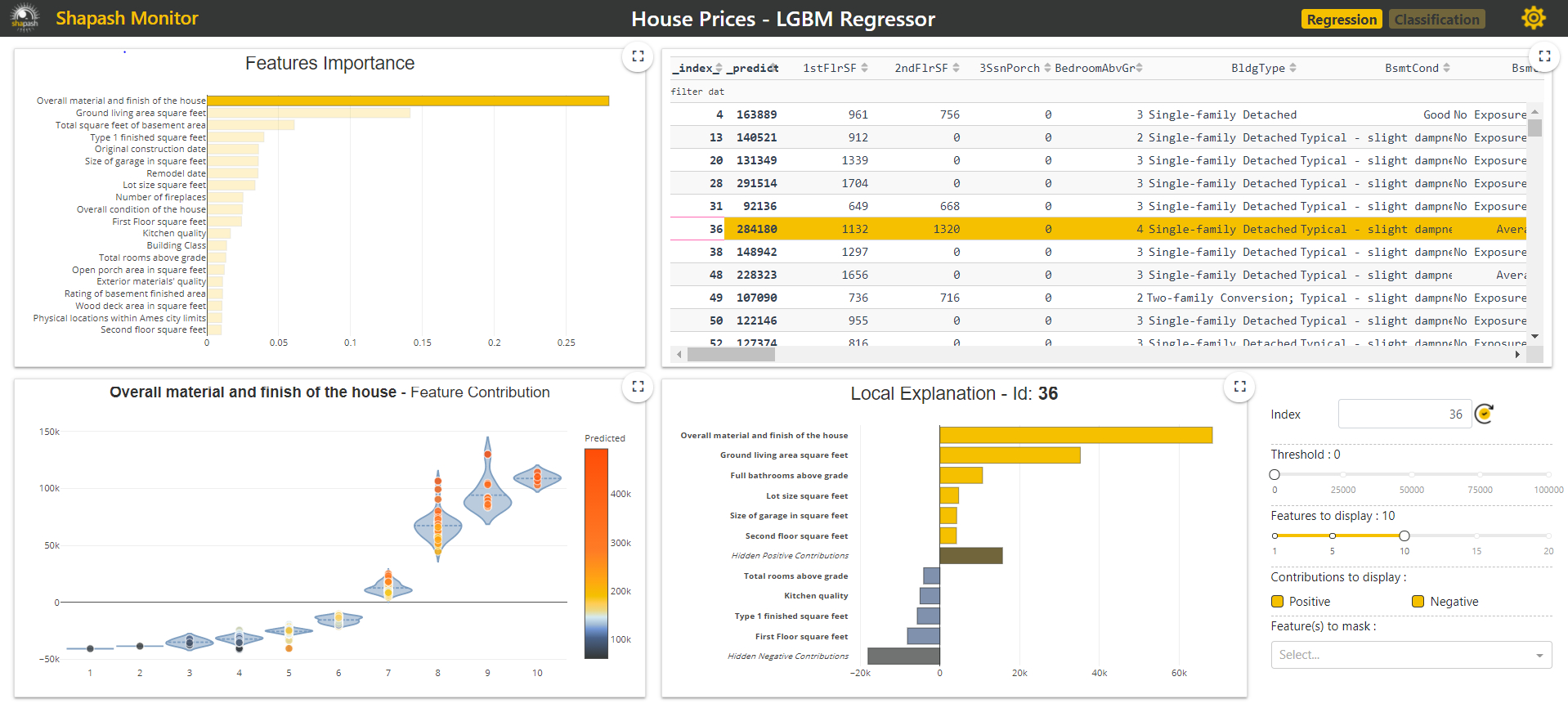
Un bel outil pour débusquer les préjugés. Pour faire mieux que les analyses au feeling.
Alors, prêt à ouvrir le capot ?


