
Au milieu du repas de Noël, juste avant le plateau de fromages, l’esprit déjà massivement alourdi par le mélange des couleurs d’alcool, Tata Huguette m’a dégainé ça :
Toi qui travaille dans l’informatique, c’est quoi cette histoire de rétro-propagation dans les réseaux de deep-learning ?
Je ne l’avais pas vu venir cette question.
Moi qui croyait qu’on allait tranquillement surfer sur les prix des maisons qui grimpent et sur l’abêtissement de la jeunesse biberonnée aux vidéos YouTube de cuisine.
Alors sur le coup, j’ai esquivé par un "ce serait trop long à expliquer".
Mais en vérité, il m’a fallu replonger un peu dedans pour en sortir un bout de code qui fonctionne (les liens sont à la fin de l’article).
Et en y repensant, c’est fascinant.
Parce qu’au fond, c’est une technique géniale pour les développeurs. Elle leur permet de coder des trucs incroyables, sans réellement comprendre pourquoi ça marche mathématiquement.
C’est la scission entre les maths et le dev.
Lorsqu’on rétorque à Yan LeCun en 2012 :
Certes, cela marche bien en pratique. Mais est-ce que cela marche en théorie ?
Une analogie immobilière
Imaginons un agent immobilier qui débute dans le métier.
Il estime le prix de vente d’une maison à partir de ce qu’il en connaît : sa situation, sa taille, son année de construction, etc...
Au départ, ses estimations sont à coté de la plaque.
Mais avec l’expérience, il va perfectionner son savoir-faire, et va s’approcher du vrai prix de vente (= celui auquel la transaction se fait finalement).
Il n’y pas réfléchi à un algorithme pour formuler son estimation. C’est venu avec le temps. A chaque transaction, il a observé de combien il s’est trompé afin de corriger le tir.
Il a tiré les leçons de ses erreurs passées pour se forger un flair.
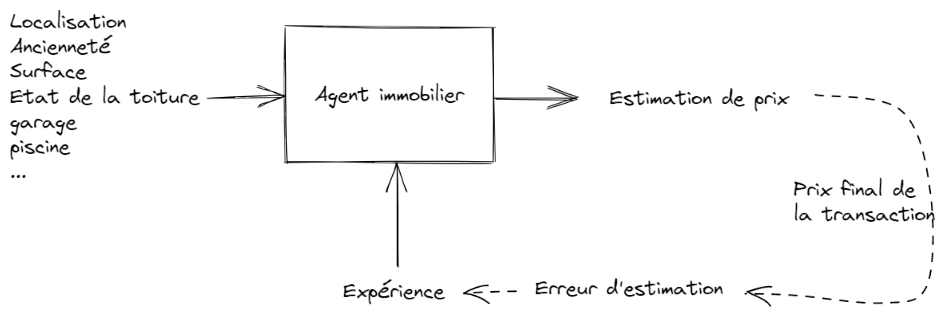
Cette boucle de retour, la rétroaction, est un pilier de la théorie de systèmes numériques.
Mais en fait, on la voit partout. Dans une équipe de rugby, dans une école, dans une entreprise : on observe le résultat de nos actions pour améliorer nos pratiques.
Une équipe d’agents immobiliers
Joe dirige une petite agence immobilière. Il a 4 employés : Alex, Bo, Casey et Debby.
Pour améliorer les estimations réalisées par son agence, voici ce qu’il décide :
- tout le monde visite le bien à estimer, et calcule sa propre estimation
- Joe fait une sélection et calcule le prix estimé final
- Il compare ce prix au vrai prix de la transaction, ça lui donne l’erreur d’estimation
- et il retourne cette erreur à ses 4 salariés pour qu’ils fassent mieux la prochaine fois.
On voit bien l’aller/retour ainsi réalisé : d’abord on estime (de gauche à droite) puis on corrige en fonction de l’erreur commise (de droite à gauche).
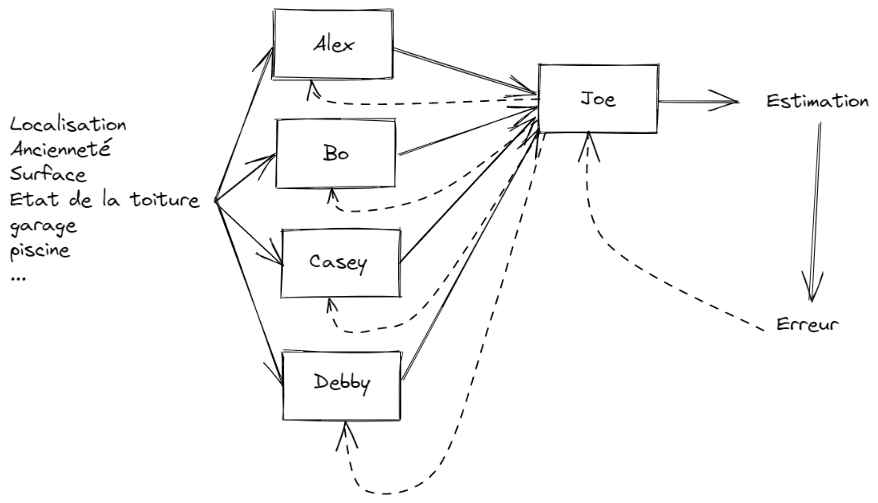
Alex, Bo, Casey et Debby vont tenir compte de l’erreur d’estimation retournée par Joe pour affiner leurs méthodes.
Joe n’a pas à se préoccuper de la façon dont les agents immobiliers s’y prennent pour formuler leurs estimations. Chacun fait à sa sauce.
Par contre, chacun ajuste sa méthode de calcul en fonction des retours de Joe.
Cet ajustement peut se faire de deux façons
- radicale : je change tout pour effacer complètement l’erreur
- progressive : j’applique une petite correction (le “taux d’apprentissage”) pour réduire l’erreur.
Tout marche à peu près bien.
Jusqu’au jour ou débarque William.
Une équipe avec 2 chefs
William, c’est le fils de l’actionnaire principal de l’agence immobilière.
Alors il n’allait pas se contenter de nettoyer les vitres.
Du coup, Joe n’est plus tout seul à superviser l’équipe. Il se partage le boulot avec William. Ensemble, ils conviennent d’un pacte : chacun fait ses estimations, on on prendra la moyenne des 2.
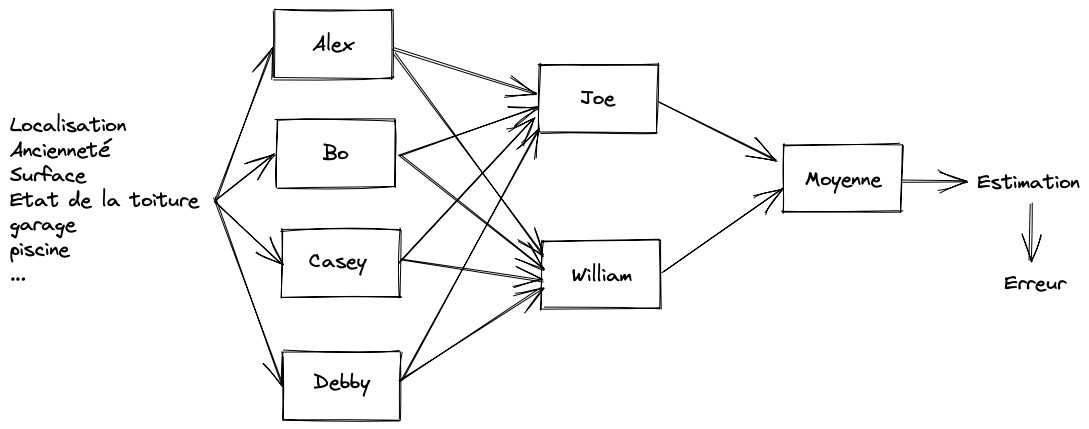
Mais pour Alex, Bo, Casey et Debby, ça devient un enfer.
Car leurs 2 chefs leur retournent du feedback différent !
Alex s’entend dire par Joe “il faudrait que tu diminues un peu ce que tu m’as envoyé”. Alors que William lui demande d’augmenter.
Joe et William ont chacun leurs façons de mixer les 4 estimations reçues !
Comment s’en sortir ?
En revenant à l’objectif de base.
Peu importe ce que veulent Joe ou William. Il n’y a qu’une seule règle qui compte : il faut qu’à la fin, l’erreur d’estimation soit la plus petite possible.
Alors eu lieu de retourner à chacun des estimateurs une erreur, on lui donne l’influence de son estimation sur l’erreur finale.
On dit à Alex :
“N’écoute pas ce que te racontent Joe et William. Sache que si tu augmentes ton estimation, ça va diminuer l’erreur finale”
Cette information, c’est le gradient de l’erreur.
Il indique à chacun la direction dans laquelle il faut aller pour réduire l’erreur.
Voila la technique qui pose les bases de l’apprentissage d’un réseau de neurones : la rétro-propagation du gradient.
Son codage n’est pas vraiment complexe (cf référence). Il repose sur du calcul matriciel, ce qui explique l’intérêt d’utiliser des composants matériels dédiés (GPU) lorsqu’on commence à entraîner de très gros modèles.
On comprend aussi que ce qui fait la performance du modèle : ça n’est pas le code.
C’est l’architecture.
L’architecture de notre modèle comporte 3 étages :
- étage n°1 : Alex, Bo, Casey, Debby
- étage n° 2: Joe et William
- étage n°3 : la moyenne (que l’on va transformer en une moyenne pondérée pour ne pas se limiter à faire 50/50)
Mais si je décide que l’étage n°2 n’est plus constitué de 2 personnes, mais de 8, pas besoin de modifier mon code ! Il me suffit de le paramétrer différemment.
L’approche du développement d’un algorithme d’IA est donc très différente des méthodes de développement habituelles on l’on passe sa journée dans le code source.
Pour développer un modèle d’IA, on passe sa journée à triturer les données d’entrées, et à comparer des architectures de modèles différentes.
L’impétueuse tentation des modèles très compliqués
Sur notre modèle très simple d’estimation de prix immobiliers, on a envie de multiplier le nombres d’agents et de superviseurs.
C’est tentant (et c’est facile).
Nos 2 superviseurs forment une sorte de couche d’IA cachée qui va deviner la formule secrète des prix. Alors augmentons leur effectif.
Inutile.
On observe que la configuration avec 4 agents immobiliers et 2 superviseurs n’est pas plus performante que celle comportant 1 seul superviseur !
On a tout intérêt à garder le modèle le plus simple possible.
Parce qu’à la fin, la valeur du modèle n’est pas dans le code source.
Elle réside dans ses paramètres. Ce sont les poids que l’on a calculé pour chacun des liens reliant les estimateurs à l’issue de la phase d’entraînement.
Ainsi, le codage d’un modèle de machine-learning n’a rien à voir avec le développement d’une application web ou mobile. Le développeur doit se transformer en analyste de données et en architecte de modèle.
Mais la compétence primaire reste la même : faire comprendre à la machine ce qu’on attend d’elle.
Références :
- Quand la machine apprend, de Yann LeCun :https://www.odilejacob.fr/catalogue/sciences-humaines/questions-de-societe/quand-la-machine-apprend_9782738149312.php
- La rétro-propagation de gradient : https://fr.wikipedia.org/wiki/Rétropropagation_du_gradient
- Exemple de code avec rétropropagation de gradient (python / pyTorch) : https://github.com/Herve07h22/pragmaticprogrammer/blob/main/real-estate-estimator/Simple_real_estate_model_pytorch.ipynb


